今天例会,梳理了工作计划后,发现要开始实现 AOI 模块了。
所谓 AOI ( Area Of Interest ) ,大致有两个用途。
一则是解决 NPC 的 AI 事件触发问题。游戏场景中有众多的 NPC ,比 PC 大致要多一个数量级。NPC 的 AI 触发条件往往是和其它 NPC 或 PC 距离接近。如果没有 AOI 模块,每个 NPC 都需要遍历场景中其它对象,判断与之距离。这个检索量是非常巨大的(复杂度 O(N*N) )。一般我们会设计一个 AOI 模块,统一处理,并优化比较次数,当两个对象距离接近时,以消息的形式通知它们。
二则用于减少向 PC 发送的同步消息数量。把离 PC 较远的物体状态变化的消息过滤掉。PC 身上可以带一个附近对象列表,由 AOI 消息来增减这个列表的内容。
在服务器上,我们一般推荐把 AOI 模块做成一个独立服务 。场景模块通知它改变对象的位置信息。AOI 服务则发送 AOI 消息给场景。
AOI 的传统实现方法大致有三种:
第一,也是最苯的方案。直接定期比较所有对象间的关系,发现能够触发 AOI 事件就发送消息。这种方案实现起来相当简洁,几乎不可能有 bug ,可以用来验证服务协议的正确性。在场景中对象不对的情况下其实也是不错的一个方案。如果我们独立出来的话,利用一个单独的核,其实可以定期处理相当大的对象数量。
第二,空间切割监视的方法。把场景划分为等大的格子,在每个格子里树立灯塔。在对象进入或退出格子时,维护每个灯塔上的对象列表。对于每个灯塔还是 O(N * N) 的复杂度,但由于把对象数据量大量降了下来,所以性能要好的多,实现也很容易。缺点是,存储空间不仅和对象数量有关,还和场景大小有关。更浪费内存。且当场景规模大过对象数量规模时,性能还会下降。因为要遍历整个场景。对大地图不太合适。这里还有一些优化技巧,比如可以把格子划分为六边形 的。
第三,使用十字链表 (3d 空间则再增加一个链表维度) 保存一系列线段,当线段移动时触发 AOI 事件。算法不展开解释,这个用的很多应该搜的到。优点是可以混用于不同半径的 AOI 区域。
接下来我要来实现这个 AOI 服务了,仔细考虑了一下,我决定简化以前做的设计 。
首先是最重要的协议设计。以前我认为,AOI 服务器应该支持对象的增删,可以在对象进入对方的 AOI 区域以及退出 AOI 区域时发出消息。
这次我重新思考了一下,觉得是可以简化的。
我只打算支持固定 AOI 半径,下面是我重新设计的协议:
typedef void * (*aoi_Alloc)(void *ud, void * ptr, size_t old_sz, size_t new_sz);
typedef void (aoi_Callback)(void *ud, uint32_t id, uint32_t id);
struct aoi_space;
struct aoi_space * aoi_create(aoi_Alloc alloc, void *ud, float radis);
void aoi_release(struct aoi_space *);
// w(atcher) m(arker) d(rop)
void aoi_update(struct aoi_space * space , uint32_t id, const char * mode , float pos[3]);
void aoi_message(struct aoi_space *space, aoi_Callback cb, void *ud);
核心只有两条协议,即最后两个 C API 。update 用来更新对象的状态;message 用来获得 aoi 消息。
这次不打算发送离开 AOI 区域的消息,而只会发送进入 AOI 区域的消息。如果对象始终维持在 AOI 区域中,尽量不发送新的消息,不确保这一点,但不会有过于频繁的消息推送。
我把对象分为两类,一类叫观察者 Watcher ,另一类是被观察者 Marker 。一个对象可以同为 Watcher 和 Marker 。在 Marker 进入 Watcher 的 AOI 区域时会触发消息。
对象用 32 位 id 表示;update 的 mode 参数用来表示这个对象是 Watcher 还是 Marker 。形式如 fopen 的 mode 参数。写上 "wm" 表示即为 Watcher 又是 Marker 。mode 还可以传入 "d" 表示 Drop 丢弃掉这个对象。
为什么不需要退出 AOI 区域的消息?我认为,在使用 AOI 服务时,往往只是用来简化比较距离的操作。收到 AOI 消息后,用户可以选择把对象加入自己关心的列表。以后在处理遍历这个列表时,有足够多的机会把不再关心的对象删掉。具体使用时,建议在对象超过两倍 AOI 距离后再取消关注。后面会看到为什么不能在对象离开 AOI 区域后立刻删除,因为那样可能导致不再收到重新进入 AOI 区域的消息。
使用时,定期调用 message 函数。每次调用称为一个 tick 。在这个 tick 里,会把发生的 AOI 事件以回调函数的形式发出来。
以上 API 很容易封装为一个网络服务,方便使用。接下来几天,我将按下面提到的算法实现这个 C 模块,并且开源。 :)
这次我不打算用打格子的方法来实现 AOI 模块。经过一番思考,我觉得我找到了一种更好的算法。
我把对象的状态分为三类。
第一类称为静止 (static) 。当一个对象在当前 tick 内没有更新坐标,就认为它是静止的。
第二类称为微动 (shift) 。当一个对象更新了坐标,但新坐标和上个关键坐标距离较小(不超过 AOI 半径的一半)时,我们认为这个对象是微动的。
第三类称为运动 (move) 。当一个对象第一次出现,或它的新坐标离上个关键点距离较大时,我们认为这个对象在运动。进入运动状态的对象会把自己的关键点坐标更新为当前位置。
在 AOI 空间中,我储存了 6 个集合对应 Watcher 和 Marker 的三类状态。一开始,这 6 个集合都是空的。
另外,在空间中还保存有四个集合,属于新增的微动对象 (shift new) 和新增的运动对象 (move new)。
在 update 函数中,新的 id 一定被加入 move new 集合。需要删除 (drop) 的 id 则简单打上 drop 标记。以前提到过的 id ,则查询更新的坐标和旧坐标的距离,更新其状态。如果有状态较之以前有改变,则分别置入 shift new 或 move new 集合。否则什么也不做。
message 函数被调用时,处理这些集合,就可以获得 AOI 消息。算法如下:
一,遍历 shift 和 move 集合,如果发现里面的对象当前 tick 没有更新,则把它放到对应的 static 集合中去。如果状态发生改变(从 shift 变成了 move 或从 move 变成了 shift )则从对应集合删掉,因为它们已经存在于 shift new 或 move new 集合中了。如果对象处于 drop 状态,则减掉对象的引用(对象用引用记数管理)。
二,把 shift new 集合里的对象和 static , shift 以及 shift new 集合里的对象逐个比较。如果他们距离较近(两倍 AOI 半径之内),则生成一个热点对,放到热点对列表中。(关于“热点对”,下文会展开解释)。这里的比较指 Watcher 集合和 Marker 集合的交叉比较。比较双方都同为 Watcher 和 Marker 时,注意只比较一次。这很容易实现,因为可以用 id 的大小来做鉴别。
三,将 move new 集合里的对象,和 static , shift , shift new, move , move new 的对象配对一一加入热点列表。不必做距离判断。
四,将 shift new 合并入 shift 集合,move new 合并入 move 集合。
五,在每个 AOI 空间中,都有一个列表,我们称为热点队列表。每个热点对,是我们需要尝试判断是否会触发 AOI 消息的两个 id 对。这个列表里会有哪些 id 对呢?如果你理解了上面几个步骤的处理,就能想到,包含有至少一个运动对象的对象对,距离比较近的微动对象对;没有完全处于静止状态的对象对,也没有距离较远的微动对象对。我们在处理这些热点对时,比较它们和上个 tick 处理时,对象状态是否发生了改变。只要至少有一个对象对象发生了改变,就将这个热点对抛弃。(因为一定有新的正确关联这两个对象的热点对在这个列表中)对于其他有效的热点对,我们比较其中两个对象的距离,当距离小于 AOI 半径时,发送 AOI 消息,并把自己从列表中删除;否则保留在列表中等待下个 tick 处理。
以上算法略微有点复杂,但实现起来并不困难。为什么它效率很高呢?
因为,如果对象处于某种速度跨越不大的运动状态中,而 AOI 距离和运动速度相比比较长,那么,运动的对象将比较长时间的停留在微动( shift )状态。如果对象停止了运动,则会切换到静止 ( static ) 状态。这两种状态之间的对象,若距离比较远,他们将不会进入热点对,及不会被遍历,也没有比较距离的运算。
只有处于运动状态的对象,会在每个 tick 和其它所有对象做一次比较。而只有少数高速运动或跳转的对象会被打上 move 标记。一般微动 (shift) 的对象则以一个周期被标记为 move 。这些操作是低频的。
完全静止的对象之间的遍历和比较则完全被优化掉了。
这篇是一个粗略的想法。大概需要这周余下的时间来实现。在实现过程中,可能会发现一些没有想到的细节,届时再来修改。
3 月 7 日:
昨天花了一天实现。发现许多可以简化和改进的地方。我认为可以把 static 以及 shift 都合并到 shift ,简化处理流程。
在实现集合的时候,一开始先用双向链表。而关系对用 hash 表。实作觉得过于复杂,就简化为数组和单向链表了。每次 message 生成的时候用一个 O(n) 的遍历生成几个需要的集合。这样比维护双向链表实现的集合的变化要简洁,性能感觉也不会有太大的损失。
代码已经放到了 github 上。大致应该是正确可用的。内存分配器可以定制,如果需要优化性能,定制一个内存分配器很重要。因为运动期动态的内存增删都是一针对 pair_list 固定大小的。专门定制可以减少内存占用,减少碎片,加快速度。实现也很简单,做一个固定大小的内存池即可。有空我会实现一个默认的定制内存分配器。
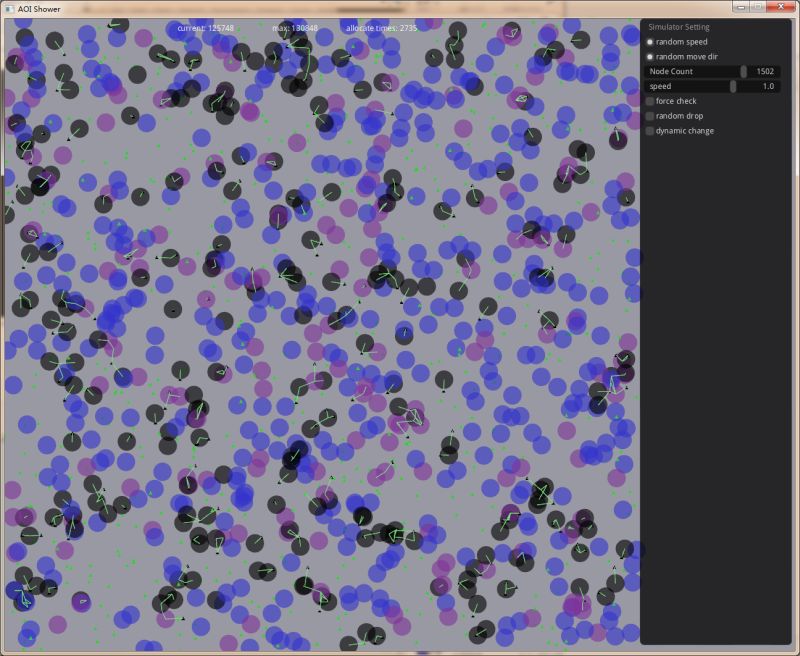
关于测试,今天小 V 同学帮我写一个一个图形化的测试程序,可以直观的看到效果,并核对有没有 AOI 消息的遗漏。大体上是没有问题的。